Grasping the Concept of LLMOps and its Utilization in Vivas.AI’s Operational Framework
As the capabilities of large language models (LLMs) continue to advance, their integration into diverse applications has revolutionized industries from customer service to content generation. However, the deployment, management, and optimization of these powerful models present unique challenges, necessitating a specialized approach known as LLMOps (Large Language Model Operations). LLMOps encompasses a comprehensive set of practices, tools, and methodologies aimed at streamlining the lifecycle of LLMs, from development and deployment to monitoring and scaling. By addressing issues such as data security, ethical considerations, and performance optimization, LLMOps ensures that these sophisticated models can be effectively and responsibly harnessed to their full potential.

What is LLMOps?
LLMOps, or Large Language Model Operations, is a specialized toolset and practice for managing big language models. It’s like caretaking for these models, overseeing their entire life from creation to retirement. This involves several stages including their development, deployment, and regular upkeep to make sure they’re running smoothly. With due credit to their size and complexity, managing these models can be quite a task, but that’s where LLMOps step in. It provides specific, customized tools and methods that not only help in managing these models efficiently but also ensure their full potential is utilized. As the field of AI grows, LLMOps is helping organizations adopt and handle these large-scale language models in their operations.
How is LLMOps different from MLOps?
To adjust MLOps practices, we need to consider how machine learning (ML) workflows and requirements change with LLMs. Key considerations include:
- Computational resources: The development and refinement of large language models necessitate engaging in computationally intensive tasks that are several orders of magnitude greater than what small-scale models require. To expedite training processes, the utilization of specialized hardware such as Graphics Processing Units (GPUs) becomes imperative. GPUs are adept at facilitating rapid data-parallel operations which significantly reduce the time required for training and fine-tuning these models. Access to such high-performance computing resources is crucial not only for the efficient training of large language models but also for their effective deployment in real-world applications. Moreover, the computational expense associated with model inference highlights the necessity of adopting techniques like model compression. These techniques are instrumental in reducing the model’s resource demands without severely compromising its performance, making the deployment more cost-effective and scalable.
- Performance metrics: Conventional machine learning models utilize well-established metrics such as accuracy, AUC (Area Under Curve), F1 score, and others that are relatively simple to compute. These metrics serve as quantitative benchmarks to assess the model’s effectiveness in making precise predictions. However, when evaluating Large Language Models (LLMs), there is a shift towards distinct, more specialized standard metrics. These include the Bilingual Evaluation Understudy (BLEU), Recall-Oriented Understudy for Gisting Evaluation (ROUGE), and Metric for Evaluation of Translation with Explicit Ordering (METEOR). Each of these metrics provides a unique lens for measuring aspects such as translation fidelity, summary quality, and sentence structure alignment. Implementing these metrics requires a deeper understanding of linguistic nuances and the specific challenges associated with natural language processing tasks. Thus, selecting and correctly applying the appropriate evaluation metric is crucial for accurately gauging the performance of LLMs.
- Prompt engineering: Models designed to follow instructions can process elaborate prompts or comprehensive sets of directives. The meticulous construction of these prompt templates is paramount in eliciting precise and dependable outputs from large language models (LLMs). Through strategic prompt engineering, it is possible to minimize occurrences of model-generated inaccuracies (often referred to as hallucinations) and to mitigate risks associated with prompt manipulation tactics, such as prompt injection. These manipulations can lead to the unintended release of confidential information and attempts to circumvent model restrictions, a practice known as jailbreaking. Thus, carefully crafting prompts not only enhances the functionality of LLMs but also fortifies their security and integrity.
- Building LLM chains or pipelines: Advanced LLM (Large Language Model) frameworks, such as LangChain and LlamaIndex, facilitate the construction of complex processing sequences that integrate multiple LLM invocations along with interactions with external systems, which may include vector databases or web-based search platforms. Such orchestrated pipelines enable LLMs to tackle intricate assignments like querying knowledge bases or providing responses to user queries grounded on specific document collections. Consequently, the focal point of LLM application development has progressively shifted towards crafting these sophisticated pipelines rather than developing novel LLM architectures.
LLMOps in Vivas.AI:
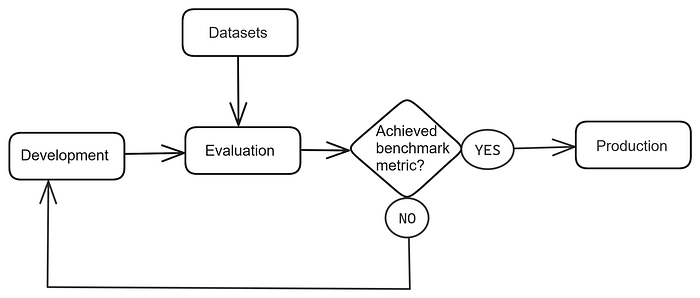
As we know LLMs are sensitive to prompt changes, and we need an automatic evaluation workflow to check any degradation in model performance. LLMOps plays a prominent role in detecting performance drops due to prompt/code changes.
- Datasets are prepared and stored in S3 with request parameters and ground truth.
- Evaluation LLM will generate a new response for the model and compare it with ground truth to check for any deviation in response. If there is any deviation, it conveys that the model has hallucinated for that data point. The developer will validate and confirm if any prompt changes are to be done.
- If there is no hallucination, prompt/code changes will be pushed to production.
LLMOps as a service in Vivas.AI:
Vivas.AI has a roadmap to offer LLMOps, as an interactive and accessible service, for the benefit of the end users. This innovative service is being designed with the intention of giving users the freedom and capability of meticulously tracking, monitoring, and assessing the efficiency, accuracy, and overall performance of their individual AI models.
Benefits of LLMOps:
- Mitigates Risks: LLMOps significantly enhance transparency and elevate the standards of monitoring, while facilitating a more agile response to requests and adhering to industry standards.
- Enhances Scalability: LLMOps equip organizations with robust tools and methodologies essential for adjusting the LLM applications’ scale to meet business requirements effectively. It ensures that LLM pipelines are reproducible, thereby facilitating smooth scaling as a natural progression of existing operations.
- Facilitates Collaboration: LLMOps serve as a hub facilitating streamlined communication and knowledge exchange among data scientists, engineers, DevOps teams, and other relevant stakeholders. By enhancing transparency, LLMOps significantly boost the collective capacity to fine-tune and optimize Large Language Models (LLMs) efficiently.
Conclusion:
In conclusion, LLMOps integrates and manages the lifecycle of large language models (LLMs) from development to deployment and maintenance. This process ensures that LLMs operate efficiently, effectively, and ethically within diverse environments. By focusing on scalability, monitoring, continuous improvement, and adherence to regulatory standards, LLMOps not only enhances the performance and applicability of LLMs but also addresses challenges such as bias, security, and resource allocation. As organizations increasingly rely on LLMs to drive insights and innovations, the implementation of robust LLMOps practices becomes crucial for sustaining advanced AI capabilities responsibly and competitively in the technological landscape.
Thank you for engaging with our community! Before you depart:
👏 Show your appreciation for this piece by applauding and following
📰 Dive deeper into a wealth of knowledge with more articles from the collection on Vivas.AI.
🔔 Stay connected and informed:
- Connect with us on LinkedIn: https://www.linkedin.com/company/80801254
- Follow us on YouTube: www.youtube.com/@vivasai7984
- Website: https://vivas.ai/
